上一篇我們知道了一些在做深度學習時的小技巧,可以分成兩種情況:在training set上效果表現不好和在testing set上表現不好。我們知道說我們在training set上表現不好的時候,我們可能要重新設計我們的model的三大流程裏面的其中一個,比如選擇別的Activation Function,或者使用不同的Adaptive Learning Rate。而在testing set上表現不好的時候,我們可以用Early Stopping,讓我們的model在overfit之前就停下來;或是我們用Regularization來防止我們的參數變得很大;又或者我們可以使用Dropout,也就是在train model的時候讓一些神經元有一定的機率被丟棄,然後在testing的時候我們不丟棄任何的神經元,但是我們讓所有的神經元的weight都減少50%(假設你的dropout rate是50%)。
今天我們要介紹的是我們這個系列的文章的第二篇有關Network的架構——Self-attention。這個架構是爲了解決一件事,那就是當我們的input是一個比較複雜的input,而不是簡單的固定長度的vector的時候,我們就需要用到Self-attention這樣的架構。
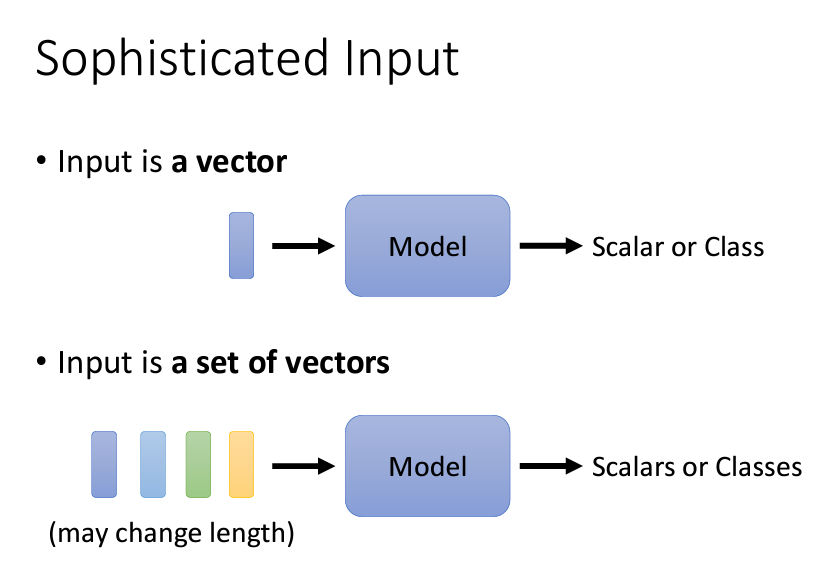
要説input有什麽好複雜的呢?我們可以用三個例子來向大家解釋:
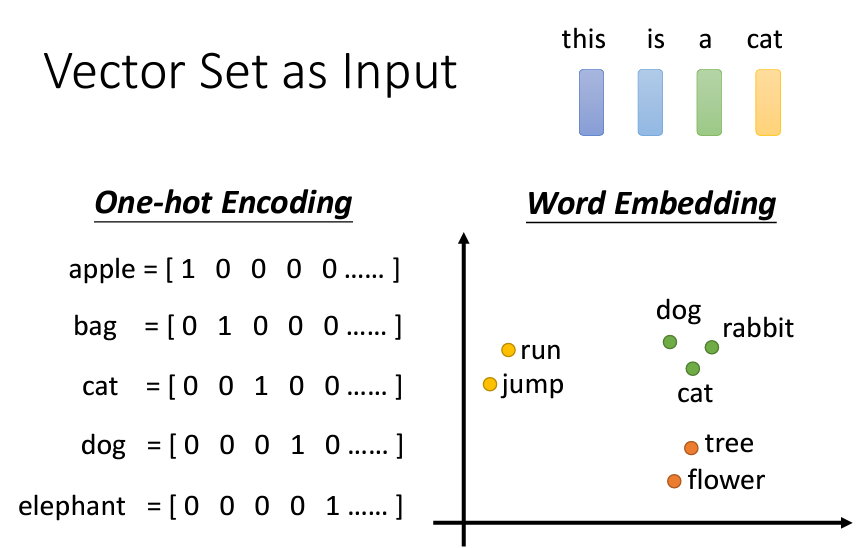
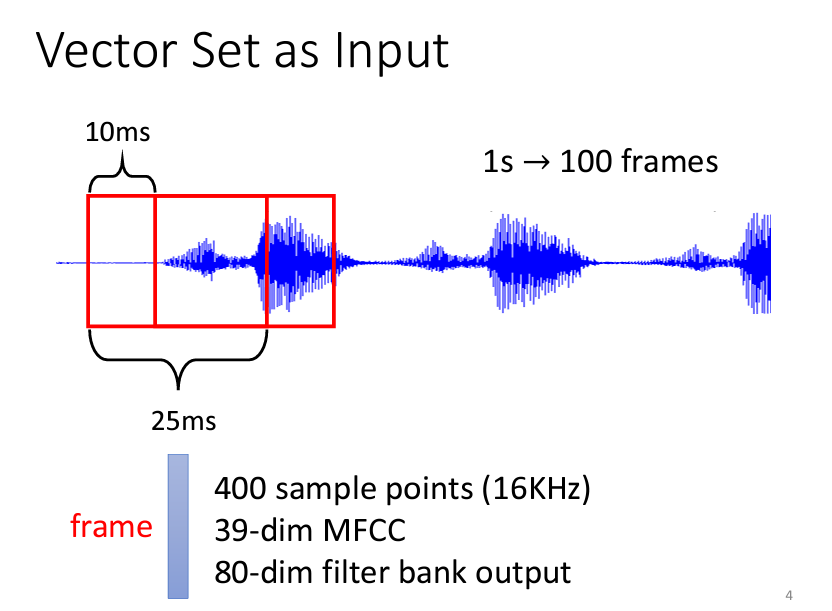
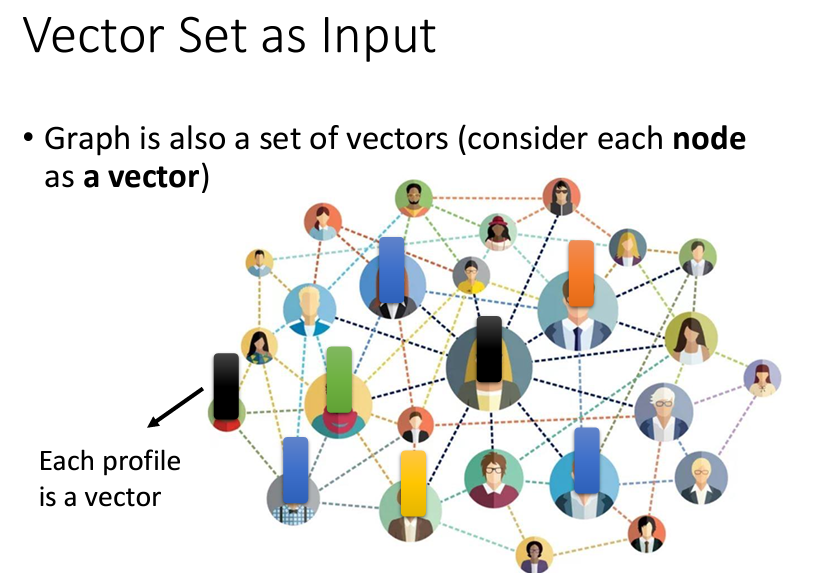
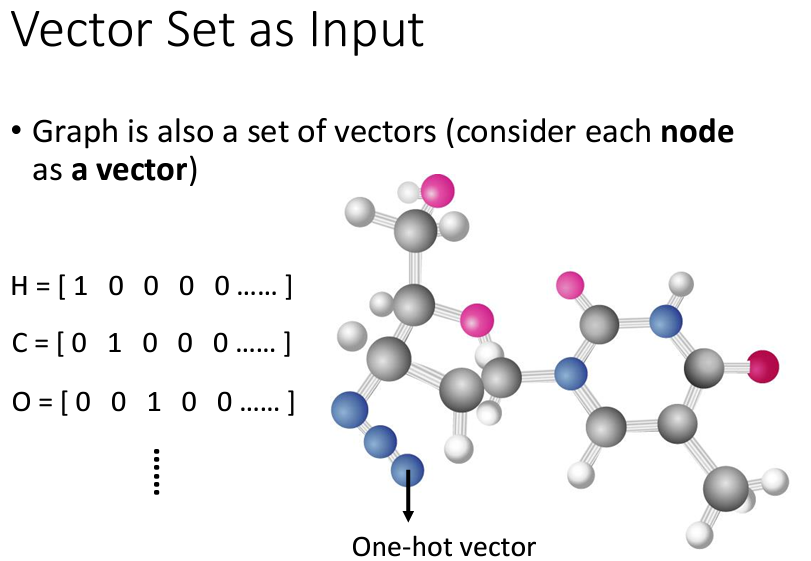
講完了輸入,現在讓我們來説一説輸出是什麽。我們可以將Self-attention的輸出分爲三個情況:
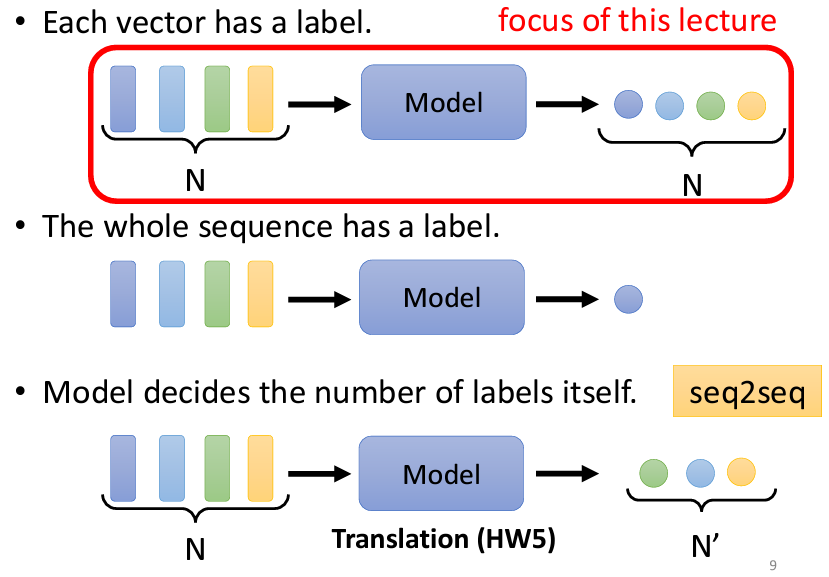
那麽我們這次只會介紹三個output裏面的第一項,也就是每個vector都有一個label的情況,我們該怎麽做。這種輸入和輸出一樣多的情況,我們叫做Sequence Labeling,我們要對這個sequence裏面的每個向量都標上label。
如果用我們學過的Fully-Connected的Network來解這個問題,比如説判斷一個句子裏面的單字是哪一個詞類(名詞、形容詞、動詞……),如果一個句子遇到的兩次同一個單子,可是代表的意思完全不一樣,那麽我們就可能要考慮上下文,比如説設立一個window,把它前後的5個字一起包裹起來去計算等方法。可是要用著一個方法,我們就必須知道整個sequence裏面,最長的句子是哪一個,才有可能把整個我們要考慮的上下文囊括進來(因爲每個句子的長度可能是不一樣的,我們必須取最大的),這樣不僅計算量大,還會導致參數變得非常多,進而增加overfitting的可能性,所以我們不會用一個Fully-Connected的Network來做。至於具體怎麽用Self-attention來解決,就讓我們在下一篇娓娓道來。
以上的内容來自於臺大教授李宏毅:鏈接,我只是把他的影片寫成了筆記。

